

Top GPT-3 Statistics
Some of the interesting statistics from GPT-3 are stated below:
- GPT-3 is way ahead of existing models with 175B trainable parameters [1].
- GPT-3 has the largest training data, a whooping 45TB [2].
- GPT-3 is being used by over 300 applications [3].
- As of March 2021, an average of 4.5B words are generated per day [3].
- Algolia tested GPT-3 on 2.1M news articles and get 91% precision [3].
- GPT-3 is 117x more complex than GPT-2 [10].
GPT-3 Models & Parameters
Various Natural Language Processing models are available and kept evolving. Prominent GPT-3 ranking statistics in terms of various models are as follows:
- The deep learning model’s training resources doubled every 3.4 months during the last decade [4].
- A 300K times increase in computational resources is observed between 2012 and 2018 [4].
- Currently, GPT-3 has the largest data corpus 45TB trained with 499 Billion tokens [2].
- A previous model T5 was trained on only a 7TB dataset [6].
- GPT-3 has 175B trainable parameters [1].
- GPT-3’s disruptive technology shows that ~70% of software development can be automated [7].
- Earlier NLP models, ELMo, had 94M parameters, BERT had 340M, GPT-2 had 1.5B, and Turing NLG had 17B [8].
- BERT by Google has 470x fewer parameters than GPT-3 [9].
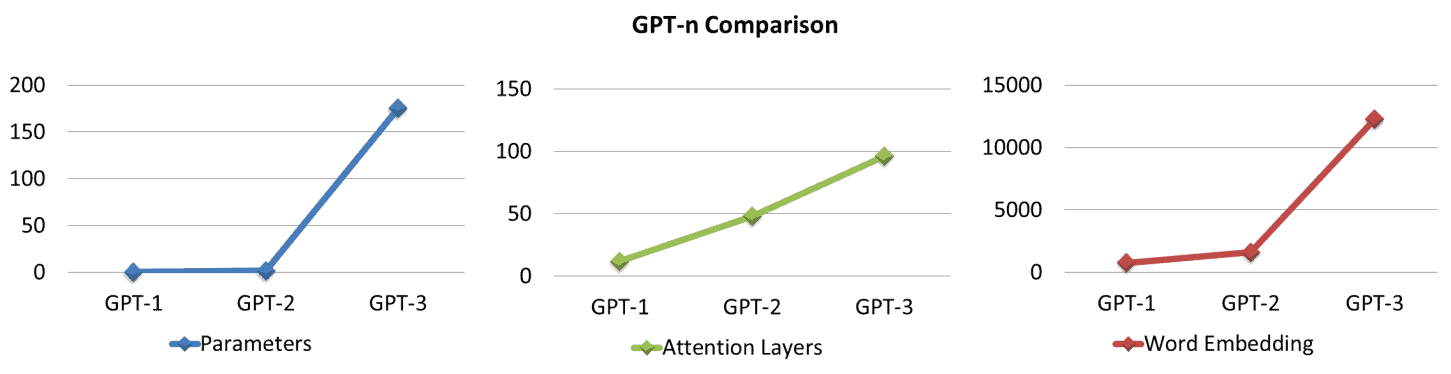
- GPT-3 contains 100x more parameters than its predecessor GPT-2 [1].
- GPT-3 has 10x more parameters than Microsoft’s Turing NLG model [1].
- The capacity of GPT-n models is enhanced by 3 orders of magnitudes with GPT-3.
- GPT-3 is 117x complex than GPT-2 [10].
- GPT-3 outperformed SOTA for the LAMBDA dataset with an 8% efficiency improvement [2].
- Compared to SOTA which provides 60% accuracy for two-digit addition and subtraction GPT-3 Fine-tuned model depicts 100% [11].
- GPT-3 based Algolia accurately answers complex natural language questions 4x better than BERT [3].
- As of November 2021, Microsoft has announced a larger model Megatron-Turing NLG with 530B parameters [8].
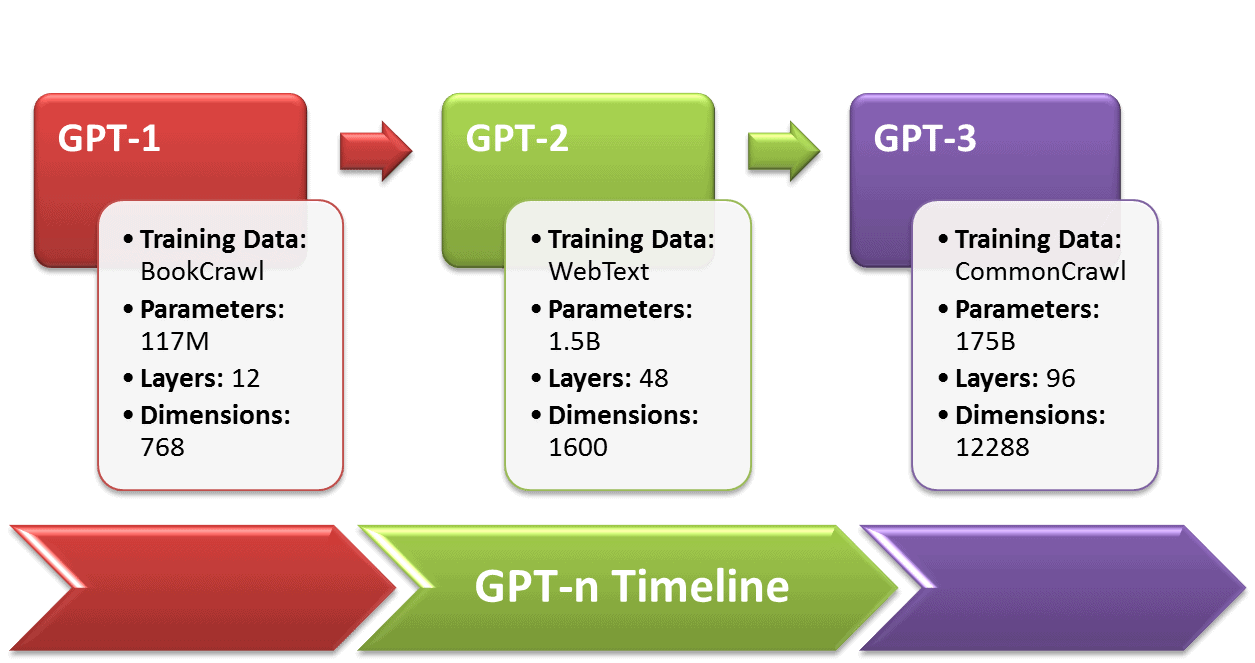
GPT-n Timeline
In 2018, the GPT-n series was initiated by OpenAI to enhance the NLP models i.e. human-like speech, text, and coding. A statistical comparison of GPT-n is provided below: [1]
- GPT-1 has 12-layers with 12 attention heads and a 768-dimensional state.
- GPT-1’s training data, BooksCorpus, had almost 7000 unpublished books amounting to ~5GB of text.
- GPT-1 performed well in 9 out of 12 tasks compared with supervised SOTA models along with decent zero-shot performance on various tasks.
- GPT-2, a successor to GPT-1 launched in 2019, is trained on 10x the parameters and amount of data as GPT-1.
- GPT-2 has 1.5B parameters and 40GB dataset, WebText, including 8M web pages.
- GPT-2 provided improved results for 7 out of 8 existing SOTA models and also performed well in the zero-shot setting.
- GPT-3 outperforms prior language models with 100x parameters than GPT-2.
- GPT-3 has 175B trainable parameters and 12288-word embedding (dimensions).
|
Model |
Launch Year |
Training Data |
Training Parameters |
Attention Layers |
Word Embedding |
Attention Heads |
|
GPT-1 |
2018 |
7000 Books ~5GB |
117M |
12 |
768 |
12 |
|
GPT-2 |
2019 |
8 million documents ~40GB |
1.5B |
48 |
1600 |
48 |
|
GPT-3 |
2020 |
Multiple Source ~45TB |
175B |
96 |
12288 |
96 |
GPT-3 Training Model Statistics
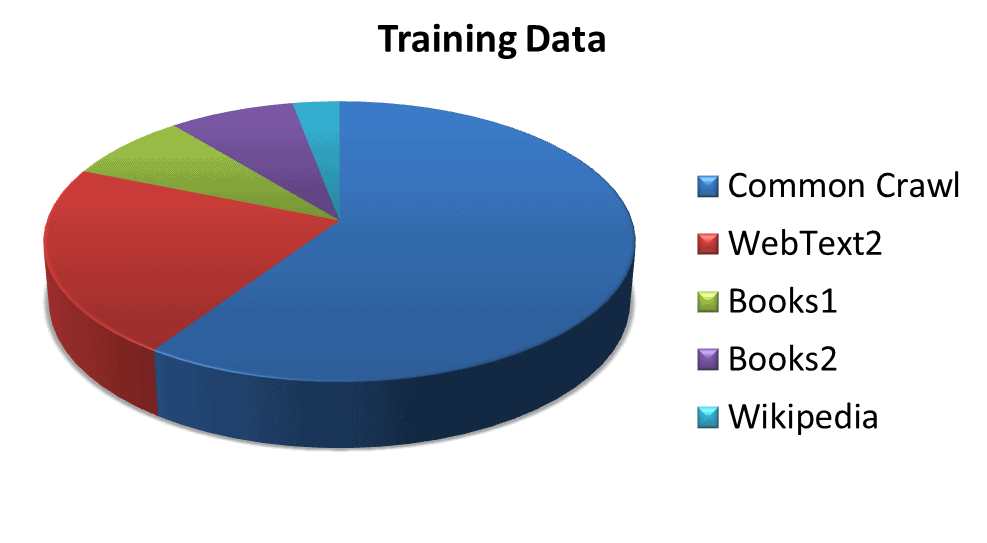
The statistics of multiple datasets used to train the model are as follows:
- GPT-3 is trained with total 499B tokens, or 700GB [2].
- Common Crawl weighted 60%, contains diverse data from web crawling over years [2].
- WebText2 spanning 22%, includes the dataset from outbound Reddit links [2].
- Books1 and Books2 with a combined share of 16%, contain internet-based books corpora [2].
- Wikipedia weighted 3%, includes data from Wikipedia pages in English [2].
|
Dataset |
Tokens |
Dataset Weightage in Training |
|
Common Crawl (filtered) |
410 billion |
60% |
|
WebText2 |
19 billion |
22% |
|
Books1 |
12 billion |
8% |
|
Books2 |
55 billion |
8% |
|
Wikipedia |
3 billion |
3% |
Source: (https://arxiv.org/pdf/2005.14165.pdf)
GPT-3 Business Model Statistics
GPT-3 is not available as open source but through a commercial API. Some of the astonishing stats regarding the company’s status and running cost of GPT-3 are as follows:
- In 2015, OpenAI began as a nonprofit research lab.
- In 2019, OpenAI switched from a non-profit organization to a for-profit company [5].
- Microsoft partnered with OpenAI with a $1B investment [12].
- GPT-3 training requires 3.114×1023 FLOPS (floating-point operations) which cost $4.6M using a Tesla V100 cloud instance at $1.5/hour and take 355 GPU-years [13].
- GPT-3 can’t be trained on a single GPU but requires distributed system increases the cost of training the final model by 1.5x – 5x [14].
- The R&D cost of GPT-3 ranges from $11.5M to $27.6M, excluding the overhead of parallel GPUs, salaries, and submodel costs [14].
- In parallel GPT-3 requires at least 11 Tesla V100 GPUs with 32GB memory each, at a cost of $9,000/piece summing to $99,000 for GPU cluster excluding RAM, CPU, SSD drives, and power supply [13].
- GPT-3 model cost $12.6M with at least 350GB of VRAM (half-precision FLOP at 16 bits/parameter) just to load the model and run inference, putting VRAM north of 400 GB [15].
- Hardware costs of running would be $100,000 – $150,000 neglecting power supply, cooling, and backup costs [14].
- A baseline Nvidia’s DGX-1 server, VRAM (8×16GB), costs around $130,000 including all other components for a solid performance on GPT-3 [16].
- If run in the cloud, GPT-3 requires at least Amazon’s p3dn.24xlarge, packed with 8xTesla V100 (32GB), 768GB RAM, and 96 CPU cores, and costs $10-30/hour, and a minimum of $87,000 yearly [14].
- OpenAI may work in collaboration with Microsoft on specialized hardware, such as the supercomputer leading to cost-efficient solutions [14].
- GPT-3 has a supercomputer hosted in Microsoft’s Azure cloud, consisting of 285k CPU cores and 10k high-end GPUs [17].
- The preliminary pricing plan provides OpenAI with a near-6,000-percent profit margin, providing room for much adjustment if the current business plan doesn’t bring in customers [18].
GPT-3 Pricing
OpenAI provides diverse pricing plans for its API. Some of the pricing stats are defined here,
- GPT-3 has a free plan, Start for free, for $18 in free credit for the first 3 months [19].
- Two other paid plans include a flexible ‘Pay as you go’ and a complex ‘Choose your model’ [19].
- Billing is done per 1000 tokens i.e. about 750 words [19]
- A token equals 4 characters or 0.75 words for English text [19].
- Every model has a predefined maximum context length, ranging from 1500 to 2048 tokens [20].
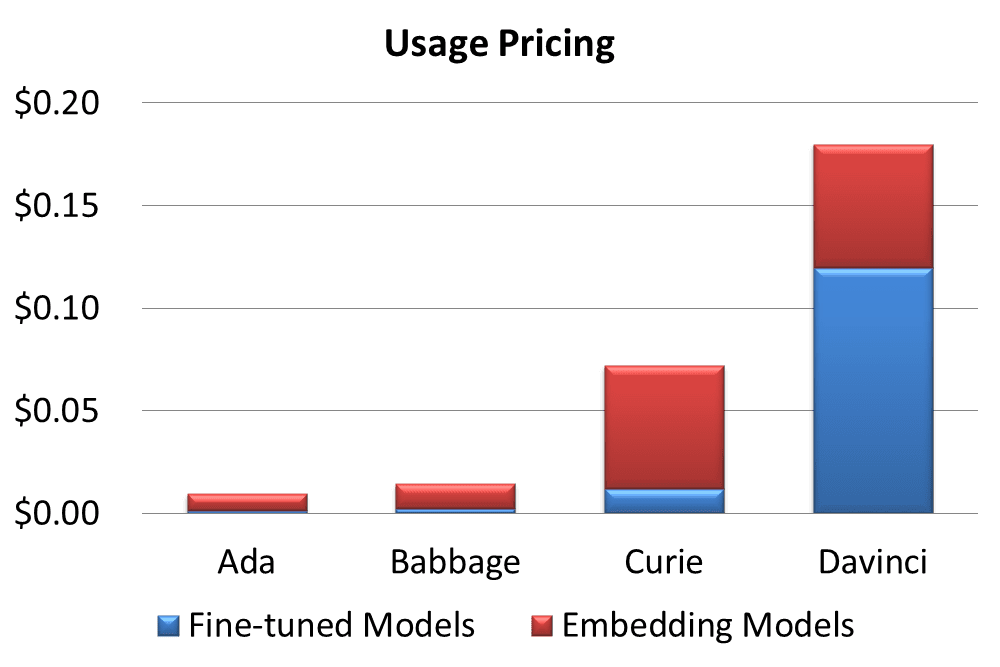
- Based on the spectrum of capabilities and choices GPT-3 provides 4 pricing models [21].
- Ada priced at $0.0008/1K tokens, performs the fastest at cost of lesser capabilities [21].
- Babbage costs $0.0012/1K tokens, is good for straightforward tasks [21].
- Curie charged $0.0060/1K tokens, has the ability for nuanced tasks, and good as a general chatbot [21].
- Davinci priced $0.0600/1K tokens gives the best results for complex intent [21].
- GPT-3 provides a customizable Fine-tuned model billed at 50% of the base price and an expensive Embedding model to build advanced search [22,23].
|
Model |
Dimensions |
Pricing / 1K Tokens |
Training / 1K Tokens |
Usage |
Usage |
|
Ada |
1024 |
$0.0008 |
$0.0004 |
$0.0016 |
$0.0080 |
|
Babbage |
2048 |
$0.0012 |
$0.0006 |
$0.0024 |
$0.0120 |
|
Curie |
4096 |
$0.0060 |
$0.0030 |
$0.0120 |
$0.0600 |
|
Davinci |
12288 |
$0.0600 |
$0.0300 |
$0.1200 |
$0.0600 |
Source: (https://openai.com/api/pricing/)
Commercialization of GPT-3 leads several service-utilizing platforms to switch to paid mode:
- PhilosopherAI declared a service cost of at least $4,000/month [24].
- AI Dungeon has introduced a premium Dragon Model for the GPT-3-based version charging $10 monthly [25].
GPT-3 Tailored Model Statistics
Customers tailor GPT-3 models suitable to their requirements and get stunning results. Here are some stats:
- Fine-tuning improves accuracy over the Grade School Math problems dataset by 2 to 4 times [26].
- A customer’s correct outputs are increased from 83% to 95% [26].
- Another customer’s error rate at reduced by 50% with a tailored model [26].
- The frequency of unreliable outputs is reduced from 17% to 5% for a customer [26].
- The benefits of fine-tuning GPT-3 start to appear in less than 100 examples [26].
The statistics of apps powered by customized GPT-3 depict promising results:
- Keeper Tax’s performance enhances from 85% to 93%, with 500 new training examples once a week [27].
- Viable reports improved accuracy from 66% to 90% in summarizing customer feedback [28].
- Sana Lab’s question and content generation yielded a 60% improvement from general grammatically correct responses to highly accurate ones [2].
- Elicit observes an improvement of 24% in understandability of results, 17% in accuracy, and 33% overall [26].
GPT-3 Model Architecture
The transformer-based model has a massive architecture divided into submodels.
- GPT-3 has 8 models based on parameter sizes ranging from 125M to 175B [2].
- Attention-based architecture has attention layers ranging from 12 in the smallest model to 96 in the largest [2].
- The transformer layers range from 12 to 96 [2].
- Learning rate changes from 6.0 × 10−4 to 0.6 × 10−4 [2].
|
Model |
Trainable Parameters |
Transformer Layers |
Bottleneck Layer Units |
Attention Layers |
Attention Head Dimension |
Batch Size |
Learning Rate |
|
GRT-3 Small |
125M |
12 |
768 |
12 |
64 |
0.5M |
6.0 × 10−4 |
|
GRT-3 Medium |
350M |
24 |
1024 |
24 |
64 |
0.5M |
3.0 × 10−4 |
|
GRT-3 Large |
760M |
24 |
1536 |
24 |
96 |
0.5M |
2.5 × 10−4 |
|
GRT-3 XL |
1.3B |
24 |
2048 |
24 |
128 |
1M |
2.0 × 10−4 |
|
GRT-3 2.7B |
2.7B |
32 |
2560 |
32 |
80 |
1M |
1.6 × 10−4 |
|
GRT-3 6.7B |
6.7B |
32 |
4096 |
32 |
128 |
2M |
1.2 × 10−4 |
|
GRT-3 13B |
13.0B |
40 |
5140 |
40 |
128 |
2M |
1.0 × 10−4 |
|
GRT-3 175B |
175.0B |
96 |
12288 |
96 |
128 |
2M |
0.6 × 10−4 |
Source: https://arxiv.org/pdf/2005.14165.pdf
GPT-3 Performance and Accuracy
The performance and accuracy of GPT-3 are studied over various existing datasets. The interesting performance stats are as follows:
- Significant performance improvement is depicted over LAMBADA and PhysicalQA (PIQA) [2].
- A prominent gain of 8% is achieved in zero-shot setting LAMBADA by GPT-3 compared to SOTA [2].
- A substantial 4% improved accuracy is depicted for PIQA compared to previous SOTA – a fine-tuned RoBERTa [2].
- HellaSwag and StoryCloze showed respectable performance but still lower than SOTA [2].
- HellaSwag results are lower compared to fine-tuned multi-task model ALUM [29].
- StoryCloze is 4.1% behind the SOTA using fine-tuned BERT model [29].
- Winograd shows 88.3%, 89.7%, and 88.6% in the zero-shot, one-shot, and few-shot settings respectively, and depicting strong results but below SOTA [13].
- GPT-3 Fine-tuned model depict 100% accuracy for two-digit addition and subtraction [11].
- Short articles (~200 words) written by GPT-3 175B are humanly detectable for change at ~52% [13].
- The articles written by GPT-3 125M are 76% human detectable. ([13])
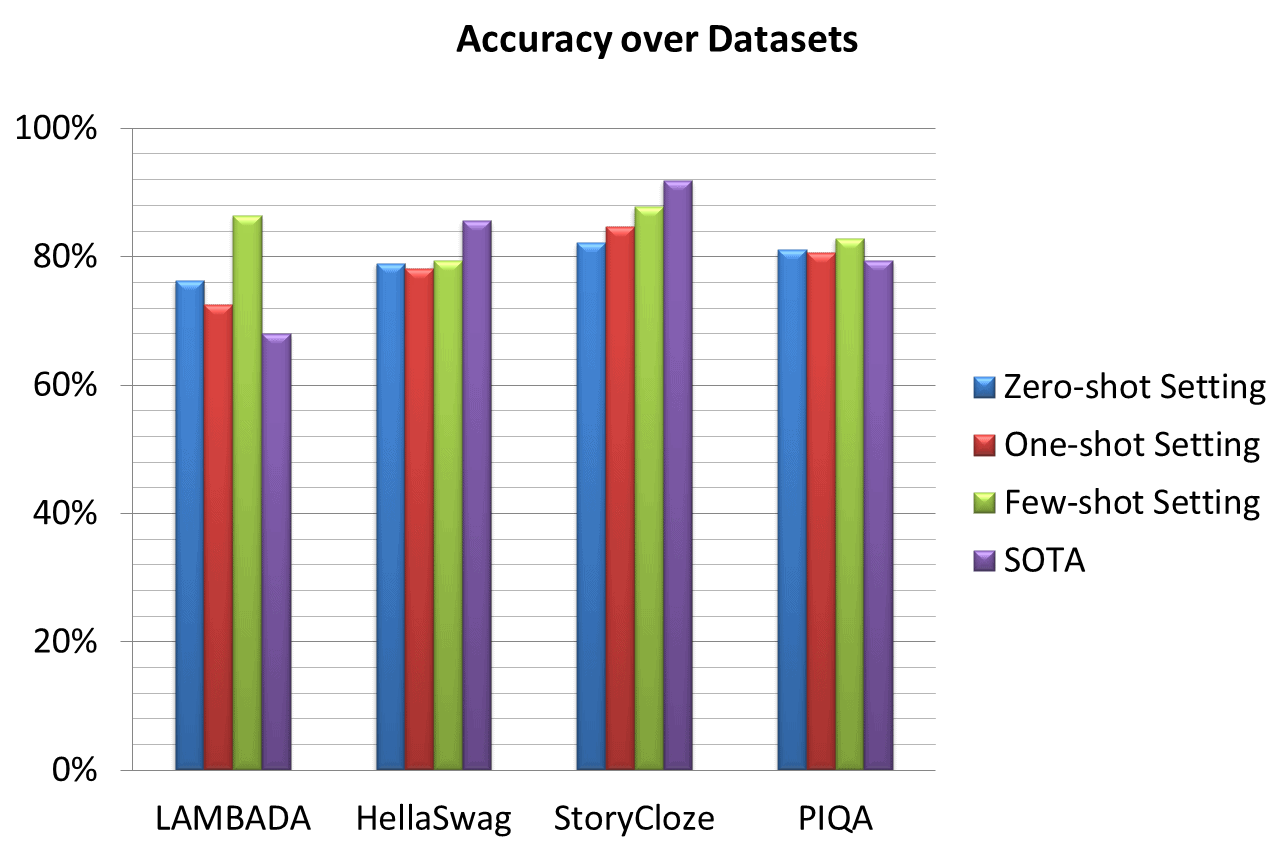
|
Dataset |
Zero-shot Setting |
One-shot Setting |
Few-shot Setting |
SOTA |
|
LAMBADA |
76.2% |
72.5% |
86.4% |
68% |
|
HellaSwag |
78.9% |
78.1% |
79.3% |
85.6% |
|
StoryCloze |
82.2% |
84.7% |
87.7% |
91.8% |
|
PhysicalQA (PIQA) |
81.0% |
80.5% |
82.8% |
79.4% |
Source: https://www.springboard.com/blog/data-science/machine-learning-gpt-3-open-ai/
GPT-3 Powered Platforms
Some of the businesses and applications utilizing GPT-3 are aforementioned in Tailored Model Statistics and Pricing Statistics. The stats of some more platforms and apps powered by GPT-3 are stated below:
- GPT-3 is being utilized by over 300 applications [30]
- The platform has tens of thousands of developers around the globe [11].
- As of March 2021 an average of 4.5B words are generated per day [30].
- Algolia tested GPT-3 on 2.1M news articles and get 91% precision [30].
- Duolingo using GPT-3 observed e 12% improvement in prediction accuracy and user engagement [31].
- DALL·E 2 based on 12B GPT-3 is preferred by 71.7of % of users for caption matching and by 88.8% for photo realism [32].
GPT-3 Use Cases
GPT-3 is a new artificial intelligence system that is said to be the most powerful AI system in the world. GPT-3 has many potential uses, including helping humans with their work, providing better customer service, and even becoming a personal assistant. Here are some of the common GPT-3 uses cases:
Business
GPT-3, the world’s largest artificial intelligence model, is now available to the public. And businesses are taking notice. Businesses are already using AI to improve customer service, create new products, and automate repetitive tasks.
Marketing
GPT-3 is a powerful tool for marketing. AI marketing tools can help you create better content, target your audience more effectively, and track your results. Additionally, GPT-3 can help you track your progress and analyze your results so that you can optimize your marketing strategies.
Customer Service
AI in customer service is revolutionizing how businesses interact with their customers. By automating routine tasks and providing instant answers to common questions, AI is helping businesses improve their customer service experience. In addition, GPT-3 powered chatbots can handle complex customer inquiries, freeing up human agents to provide more personalized service.
Data analysis
AI can help identify patterns and correlations that humans might miss. It can also help automate the analysis process, making it faster and easier. Additionally, AI can provide insights that would not be possible without its help. For these reasons, AI is becoming an essential tool for data analysts.
Content Creation
GPT-3 based AI content creation tools are being used to write articles, create videos, and even generate social media posts.
Design
AI design tools powered by GPT-3 have the potential to improve the efficiency and quality of the design process by automating repetitive tasks, providing personalized recommendations, and assisting in the exploration of design options.
GPT-3 Statistics Final Words
The article provides the GPT-3 growth story based on prominent statistics. The GPT-n models are substantially growing and the research community is curious about GPT-4. According to a reviewer at Hacker News,
References
- https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2
- https://arxiv.org/pdf/2005.14165.pdf
- https://openai.com/blog/gpt-3-apps/
- https://towardsdatascience.com/gpt-3-a-complete-overview-190232eb25fd
- (https://futurism.com/ai-elon-musk-openai-profit)
- https://www.toptal.com/deep-learning/exploring-pre-trained-models
- https://www.gartner.com/en/documents/3994660
- (https://www.i-programmer.info/news/105-artificial-intelligence/14987-the-third-age-of-ai-megatron-turing-nlg.html)
- (https://360digitmg.com/gpt-vs-bert
- https://www.datacamp.com/blog/gpt-3-and-the-next-generation-of-ai-powered-services
- (https://singularityhub.com/2021/04/04/openais-gpt-3-algorithm-is-now-producing-billions-of-words-a-day/)
- (https://www.theverge.com/2019/7/22/20703578/microsoft-openai-investment-partnership-1-billion-azure-artificial-general-intelligence-agi)
- https://lambdalabs.com/blog/demystifying-gpt-3/
- https://bdtechtalks.com/2020/09/21/gpt-3-economy-business-model/
- https://cloudxlab.com/blog/what-is-gpt3-and-will-it-take-over-the-world/
- https://medium.com/@messisahil7/gpt-3-a-new-step-towards-general-artificial-intelligence-66879e1c4a44
- https://www.endila.com/post/is-gpt-3-really-the-future-of-nlp
- https://pakodas.substack.com/p/estimating-gpt3-api-cost?s=r
- https://openai.com/api/pricing/
- https://beta.openai.com/docs/introduction/key-concepts
- https://beta.openai.com/docs/models
- https://beta.openai.com/docs/guides/fine-tuning,
- https://beta.openai.com/docs/guides/embeddings/what-are-embeddings
- https://philosopherai.com/
- (https://aidungeon.medium.com/ai-dungeon-dragon-model-upgrade-7e8ea579abfe
- https://openai.com/blog/customized-gpt-3/
- ((https://www.keepertax.com/
- https://www.askviable.com/
- https://www.springboard.com/blog/data-science/machine-learning-gpt-3-open-ai/
- https://openai.com/blog/gpt-3-apps
- https://www.wired.com/brandlab/2018/12/ai-helps-duolingo-personalize-language-learning/
- https://openai.com/dall-e-2/

